
Problem Statement
Can we determine the factors that lead to a high rating
Goals
- Determine the factors that lead to a high imdb rating for feature films
- using ratings and review data obtained from IMDB for the top films according to IMDB.
# Import our modules
# Pandas and numpy
import pandas as pd
import numpy as np
# Modules for webscraping from webpages and apis
import urllib
import requests
import json
from bs4 import BeautifulSoup
# Using re for string matching
import re
# matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
Lets use imdbpie to grab the top 250 movies
# import Imdb from imdbpie
from imdbpie import Imdb
# grab top 250 movies using imdbpie
imdb = Imdb()
imdb = Imdb(anonymize=True)
top_250 = imdb.top_250()
df_250 = pd.DataFrame(top_250)
# Check for the oldest movie in the list
df_250['year'].min()
u'1921'
# Pull ids out into list
ids_250 = df_250['tconst']
import pickle
# Save list of ids out with pickle
with open('ids_250_pickle', 'wb') as fp:
pickle.dump(ids_250, fp)
with open ('ids_250_pickle', 'rb') as fp:
ids_250 = pickle.load(fp)
Lets grab a bunch of movie title ids from imdb
from the past 100 years or so, making sure we cover the timespan of our top 250.
We will go back a few years before the oldest movie in the top 250 to make sure we grab
some titles that may have been previously made with some of the same team
# Function to request and soupify our results
def soupy(url):
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
response = requests.get(url, headers=headers)
content = response.content
soup = BeautifulSoup(content, "lxml")
return soup
# url formaters, search imdb by year (from 1910 -) and grab first 3 pages (150 most popular movies) for each year
year_url = 'http://www.imdb.com/search/title?year={},{}&title_type=feature&sort=moviemeter,asc&page={}&ref_=adv_nxt'
years = range(1910,2018)
pages = range(1,4)
# Function to grab title ids from imdb search pages
def get_titles(url):
soup = soupy(url)
try:
titles = soup.findAll('h3', class_="lister-item-header")
for i in titles:
tt_link = i.find('a')['href']
tt_id = tt_link.split('/')[2]
title_ids.append(tt_id)
except AttributeError:
tt_id = None
# Instantiate an empty list to hold our ids
title_ids = []
# Loop over each year and the first three pages to grab title ids
for year in years:
for page in pages:
get_titles(year_url.format(year,year,page))
len(title_ids)
16132
# Append top 250 ids to most popular per year
for i in ids_250:
title_ids.append(i)
# Delete duplicate ids
title_ids_set = list(set(title_ids))
len(title_ids_set)
16136
# Pickle ids
with open('ids_pickle', 'wb') as fp:
pickle.dump(title_ids_set, fp)
Lets test grabbing our info using both the OMDBapi and imdb-pie
%%timeit -o
# Time first 100 from OMDB
title_request = 'http://www.omdbapi.com/?i={}&plot=full'
info_omdb = []
for i in title_ids_set[:50]:
url = title_request.format(i)
response = requests.get(url)
info_omdb.append(response.json())
1 loop, best of 3: 3.66 s per loop
<TimeitResult : 1 loop, best of 3: 3.66 s per loop>
%%timeit -o
# Time first 100 from OMDB
title_request = 'http://www.omdbapi.com/?i={}&plot=full'
info_omdb = []
for i in title_ids_set[:50]:
url = title_request.format(i)
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
response = requests.get(url, headers=headers)
info_omdb.append(response.json())
1 loop, best of 3: 2.95 s per loop
<TimeitResult : 1 loop, best of 3: 2.95 s per loop>
%%timeit -o
# Time first 100 from imdbpie
info_imdbpie = []
for i in title_ids_set[:50]:
title = imdb.get_title_by_id(i)
info_imdbpie.append(title)
1 loop, best of 3: 1min 47s per loop
<TimeitResult : 1 loop, best of 3: 1min 47s per loop>
# Take a look at the OMDB info
info_omdb_df = pd.DataFrame(info_omdb)
info_omdb_df.head(2)
| Actors | Awards | Country | Director | Genre | Language | Metascore | Plot | Poster | Rated | Released | Response | Runtime | Title | Type | Writer | Year | imdbID | imdbRating | imdbVotes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | N/A | N/A | Poland | Aleksander Hertz | N/A | Polish | N/A | N/A | N/A | N/A | N/A | True | N/A | Historia, jakich wiele | movie | N/A | 1912 | tt0437222 | N/A | N/A |
| 1 | John Agar, Joyce Meadows, Robert Fuller, Thoma... | N/A | USA | Nathan Juran | Action, Adventure, Horror | English | N/A | Gor, a powerful criminal brain from the planet... | https://images-na.ssl-images-amazon.com/images... | APPROVED | 01 Oct 1957 | True | 71 min | The Brain from Planet Arous | movie | Ray Buffum (screenplay) | 1957 | tt0050210 | 5.3 | 1,109 |
# Take a look at the imdbpie info
# info_imdbpie
feats = ['rating','title', 'year', 'cast_summary', 'genres', 'imdb_id', 'directors_summary', 'certification','type']
df_imdbpie_test = pd.DataFrame([{fn: getattr(f, fn) for fn in feats} for f in info_imdbpie])
df_imdbpie_test.head(2)
| cast_summary | certification | directors_summary | genres | imdb_id | rating | title | type | year | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | [] | None | [<Person: Aleksander Hertz (nm0381076)>] | None | tt0437222 | NaN | Historia, jakich wiele | feature | 1912 |
| 1 | [<Person: John Agar (nm0000730)>, <Person: Joy... | Approved | [<Person: Nathan Juran (nm0432846)>] | [Action, Adventure, Horror, Sci-Fi, Thriller] | tt0050210 | 5.3 | The Brain from Planet Arous | feature | 1957 |
Which should we use?
The OMDBapi is working quite a bit faster than imdbpie here. And looking at the data it returns
(a json item) it will be easier to bring into a dataframe.
Imdbpie returns class instances with some embedded classes within them that will need a few more steps
to clean when bringing into a dataframe.
Though Imdb-pie’s info is a bit more complete(includes producers, music … in credits),
So, I will use the OMDBapi, given that it is working about 16 times faster, and go back to
scrap a few other items from IMDB’s site.
Now lets grab the info for all of our titles using the OMDbapi
# List to capture title info
movie_info = []
# Grab info for all titles using omdbapi
# The list of ids was subsetted and rerun for each group to avoid overloading the api
for t in title_ids_set[16000:]:
args = {'i':t,'plot':'short','r':'json', 'tomatoes':'True'}
url = 'http://www.omdbapi.com/'
r = requests.get(URL, params=args)
movie_info.append(r.json())
# Convert info to dataframe
movie_df = pd.DataFrame(movie_info)
# Drop any duplicates
movie_df.drop_duplicates(subset='imdbID', inplace=True)
(16137, 36)
# Drop any null ids that resulted from our connection being kicked
movie_df = movie_df[movie_df.imdbID.notnull()]
movie_df.shape
(16136, 36)
# Export dataframe with pickle
movie_df.to_pickle('movie_df.pkl')
# Import dataframe with pickle
movie_df = pd.read_pickle('movie_df.pkl')
movie_df.head(2)
| Actors | Awards | BoxOffice | Country | DVD | Director | Error | Genre | Language | Metascore | ... | tomatoFresh | tomatoImage | tomatoMeter | tomatoRating | tomatoReviews | tomatoRotten | tomatoURL | tomatoUserMeter | tomatoUserRating | tomatoUserReviews | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | N/A | N/A | N/A | Poland | N/A | Aleksander Hertz | NaN | N/A | Polish | N/A | ... | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| 1 | John Agar, Joyce Meadows, Robert Fuller, Thoma... | N/A | N/A | USA | 27 Feb 2001 | Nathan Juran | NaN | Action, Adventure, Horror | English | N/A | ... | N/A | N/A | N/A | N/A | N/A | N/A | http://www.rottentomatoes.com/m/the_brain_from... | N/A | N/A | N/A |
2 rows × 36 columns
movie_df.columns
Index([u'Actors', u'Awards', u'BoxOffice', u'Country', u'DVD', u'Director',
u'Error', u'Genre', u'Language', u'Metascore', u'Plot', u'Poster',
u'Production', u'Rated', u'Released', u'Response', u'Runtime', u'Title',
u'Type', u'Website', u'Writer', u'Year', u'imdbID', u'imdbRating',
u'imdbVotes', u'tomatoConsensus', u'tomatoFresh', u'tomatoImage',
u'tomatoMeter', u'tomatoRating', u'tomatoReviews', u'tomatoRotten',
u'tomatoURL', u'tomatoUserMeter', u'tomatoUserRating',
u'tomatoUserReviews'],
dtype='object')
# Drop unneeded columns
drop_columns = [u'DVD', u'Error', u'Poster', u'Response', u'Type', u'Website',
u'tomatoConsensus', u'tomatoFresh', u'tomatoImage',
u'tomatoMeter', u'tomatoRating', u'tomatoReviews', u'tomatoRotten',
u'tomatoURL', u'tomatoUserMeter', u'tomatoUserRating',
u'tomatoUserReviews']
movie_df.drop(drop_columns, axis=1, inplace=True)
movie_df.head(2)
| Actors | Awards | BoxOffice | Country | Director | Genre | Language | Metascore | Plot | Production | Rated | Released | Runtime | Title | Writer | Year | imdbID | imdbRating | imdbVotes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | N/A | N/A | N/A | Poland | Aleksander Hertz | N/A | Polish | N/A | N/A | N/A | N/A | N/A | N/A | Historia, jakich wiele | N/A | 1912 | tt0437222 | N/A | N/A |
| 1 | John Agar, Joyce Meadows, Robert Fuller, Thoma... | N/A | N/A | USA | Nathan Juran | Action, Adventure, Horror | English | N/A | Gor, a powerful criminal brain from the planet... | Howco International | APPROVED | 01 Oct 1957 | 71 min | The Brain from Planet Arous | Ray Buffum (screenplay) | 1957 | tt0050210 | 5.3 | 1,109 |
# Replace N/A with nan
movie_df = movie_df.applymap(lambda x: np.nan if x == 'N/A' else x)
movie_df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 16136 entries, 0 to 20459
Data columns (total 19 columns):
Actors 15980 non-null object
Awards 7468 non-null object
BoxOffice 2099 non-null object
Country 16038 non-null object
Director 16029 non-null object
Genre 15577 non-null object
Language 14905 non-null object
Metascore 3542 non-null object
Plot 14557 non-null object
Production 11848 non-null object
Rated 11635 non-null object
Released 15490 non-null object
Runtime 14789 non-null object
Title 16136 non-null object
Writer 15746 non-null object
Year 16136 non-null object
imdbID 16136 non-null object
imdbRating 14937 non-null object
imdbVotes 14931 non-null object
dtypes: object(19)
memory usage: 2.5+ MB
# Drop titles without an imdb rating
rated_df = movie_df[movie_df['imdbRating'].notnull()]
rated_df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 14937 entries, 1 to 20459
Data columns (total 19 columns):
Actors 14876 non-null object
Awards 7460 non-null object
BoxOffice 2098 non-null object
Country 14913 non-null object
Director 14896 non-null object
Genre 14750 non-null object
Language 14265 non-null object
Metascore 3542 non-null object
Plot 14188 non-null object
Production 11779 non-null object
Rated 11602 non-null object
Released 14529 non-null object
Runtime 14456 non-null object
Title 14937 non-null object
Writer 14798 non-null object
Year 14937 non-null object
imdbID 14937 non-null object
imdbRating 14937 non-null object
imdbVotes 14931 non-null object
dtypes: object(19)
memory usage: 2.3+ MB
rated_df.reset_index(drop=True, inplace=True)
rated_df.to_pickle('rated_films_first.pkl')
Link to notebook used to scrape budget and producer info
https://git.generalassemb.ly/anthonysull/project-6-apis-randomforests/blob/master/P6_Budget_Gross_Producers.ipynb
Cleaning
Let’s convert our numeric features to numeric
import warnings
warnings.filterwarnings('ignore')
# Strip imdbvotes string of commas
rated_df['imdbVotes'] = rated_df.loc[:,'imdbVotes'].str.replace(',','')
# List of columns to convert to numeric
to_convert = ['imdbRating', 'Metascore', 'Year', 'imdbVotes']
# Loop through list of columns and convert
for i in to_convert:
rated_df[i] = rated_df.loc[:,i].apply(pd.to_numeric)
rated_df.describe()
| Metascore | Year | imdbRating | imdbVotes | |
|---|---|---|---|---|
| count | 3542.000000 | 14937.000000 | 14937.000000 | 1.493100e+04 |
| mean | 57.476285 | 1966.674299 | 6.528560 | 3.425068e+04 |
| std | 18.419900 | 29.252732 | 1.041723 | 9.456518e+04 |
| min | 1.000000 | 1910.000000 | 1.300000 | 5.000000e+00 |
| 25% | NaN | 1942.000000 | 6.000000 | NaN |
| 50% | NaN | 1967.000000 | 6.700000 | NaN |
| 75% | NaN | 1992.000000 | 7.200000 | NaN |
| max | 100.000000 | 2017.000000 | 9.500000 | 1.771273e+06 |
Convert release date to datetime
# Lets convert release date to datetime
from datetime import datetime
rated_df['Release_Date'] = pd.to_datetime(rated_df.loc[:,'Released'],format='%d %b %Y')
Clean production column
rated_df.Production.nunique()
1549
rated_df.Production.value_counts()[:25]
Paramount Pictures 718
MGM 565
Universal Pictures 443
Warner Home Video 431
Warner Bros. Pictures 425
United Artists 390
20th Century Fox 369
Columbia Pictures 356
MGM Home Entertainment 321
20th Century Fox Film Corporation 308
Warner Bros. 307
Sony Pictures Home Entertainment 290
Criterion Collection 241
MCA Universal Home Video 215
WARNER BROTHERS PICTURES 204
Twentieth Century Fox Home Entertainment 201
Universal 192
Sony Pictures Entertainment 141
Paramount Home Video 137
Sony Pictures 108
New Line Cinema 100
Miramax Films 96
RKO Pictures 93
Fox 92
RKO Radio Pictures 91
Name: Production, dtype: int64
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
choices = set(rated_df['Production'])
process.extract('Fox', choices, limit=15)
[(u'Fox', 100),
(u'20th Century Fox', 90),
(u'Fox Lorber', 90),
(u'Century Fox', 90),
(u'Fox Walden', 90),
(u'Fox Home Entertainment', 90),
(u'Fox Atomic', 90),
(u'Fox Films', 90),
(u'Fox Searchlight', 90),
(u'Fox International', 90),
(u'Fox Film Corporation', 90),
(u'Twentieth Century Fox', 90),
(u'Fox Searchlight Pictures', 90),
(u'CBS/Fox', 90),
(u'20th Century-Fox', 90)]
# Create a dictionary of production company replacements
replacements = {
'Production': {
r'^Howco.*': 'Howco International Pictures',
r'^Sony.*': 'Sony Pictures',
r'^Twentieth Century.*': '20th Century Fox',
r'^20th.*': '20th Century Fox',
r'^Century Fox': '20th Century Fox',
r'^Fox Film.*': '20th Century Fox',
r'^Fox International': '20th Century Fox',
r'^Fox Home.*': '20th Century Fox',
r'^Fox': '20th Century Fox',
r'^Fox Searchlight.*': 'Fox Searchlight',
r'^21st Century.*': '21st Century Film',
r'^Tri[\sSs][St].*': 'TriStar Pictures',
r'^Columbia Tr.*': 'TriStar Pictures',
r'^Columbia.*': 'Columbia Pictures',
r'^Cosm.*': 'Cosmopolitan Productions',
r'^Toho.*': 'Toho Company',
r'^MGM.*': 'MGM',
r'^Metro[ -]G.*': 'MGM',
r'^Metro.*':'Metro Pictures',
r'^Vestron.*':'Vestron Pictures',
r'^Milestone Fil.*':'Milestone Film',
r'^W[Aa][Rr]?[Nn][Ee][Rr]s?\s?[BH].*':'Warner Brothers',
r'^WARNER': 'Warner Brothers',
r'^Warner I.*': 'Warner Independent',
r'^Walter W.*':'Walter Wanger',
r'^Water Bearer.*':'Water Bearer Films',
r'^Arthur Mayer.*':'Arthur Mayer Edward Kingsley I',
r'^Path[^f].*': 'Pathe',
r"^Lions?[Gg].*.*": 'Lionsgate Films',
r"^Lions?'?s?\sG.*": "Lion's Gate Films",
r"^MCA.*": 'MCA Universal',
r"^Universum F.*":'Universum Film',
r'^New Li.*': "New Line Cinema",
r'^New World.*':'New World Pictures',
r'^RKO.*':'RKO Pictures',
r'^Dream\s?W.*': 'DreamWorks',
r'^Paramou.*':'Paramount Pictures',
r'^Mir[ai]max.*': 'Miramax Films',
r'^Allied Artists.*':'Allied Artists Pictures',
r'^Amazon.*': 'Amazon Studios',
r'^Cinerama.*':'Cinerama',
r'^Artisan.*':'Artisan Pictures',
r'^Pacific Arts.*':'Pacific Arts',
r'^IFC.*':'IFC Films',
r'^Magnolia.*':'Magnolia Pictures',
r'^Magnet.*':'Magnet Releasing',
r'^Weinstein.*':'The Weinstein Co.',
r'^The Weinstein Co.*': 'The Weinstein Co.',
r'^Winstar.*':'Winstar Cinema',
r'^BFI.*':'British Film Institute',
r'^VCI.*':'VCI Entertainment',
r'^Home Box.*':'HBO',
r'^HBO.*':'HBO',
r'^Criterion.*':'The Criterion Collection',
r'^American Int.*':'American International Pictures',
r'^Independent Int.*':'Independent International Pictures',
r'^Independ[ae]nt Pi.*':'Independent Pictures',
r'^Relativity.*':'Relativity Media',
r'^STARZ MEDIA.*': 'Starz',
r'^Associated First National P.*': 'First National Pictures',
r'^First National P.*': 'First National Pictures',
r'^Tartan.*':'Tartan Films',
r'^Burroughs-Tarzan Ente.*':'Burroughs-Tarzan Enterprises',
r'^Focus .*':'Focus Features',
r'.*?Rogue.*':'Rogue Pictures',
r'^Anchor Bay.*':'Anchor Bay Films',
r'^Touchstone.*':'Touchstone Pictures',
r'^CBS .*':'CBS Films',
r'^De Laurentiis Ent.*':'De Laurentiis Entertainment Group',
r'.*Concorde.*':'New Horizons Pictures',
r'New Horizons.*':'New Horizons Pictures',
r'American Pop.*':'American Pop Classics',
r'Republic.*':'Republic Pictures',
r'.*Embassy.*':'Embassy Pictures',
r'^Screen Gems.*':'Screen Gems',
r'^Rialto.*':'Rialto Pictures',
r'^Summit.*':'Summit Entertainment',
r'^Dimension.*':'Dimension Films',
r'^Monogram.*':'Monogram Pictures',
r'^Open Road.*':'Open Road Films',
r'.*Goldwyn.*':'Samuel Goldwyn Films',
r'^Roadside At.*':'Roadside Attractions',
r'^PolyGram.*':'PolyGram Films',
r'^First Nation.*':'First National Pictures',
r'^Hollywood Pic.*':'Hollywood Pictures',
r'^A24.*':'A24 Films',
r'^Kino.*':'Kino',
r"^Loew's.*":"Loew's Inc.",
r'^Artkino Pict.*':'Artkino Pictures',
r'^Gramercy.*':'Gramercy Pictures',
r'Buena Vista.*': 'Buena Vista Pictures',
r'.*Disney.*': 'Disney',
r'^Dream[Ww]orks.*': 'DreamWorks',
r'^Twentieth Century Fox.*': '20th Century Fox',
r'Warner Bros\..*': 'Warner Bros.',
r'Walt Disney': 'Disney',
r'Hollywood/Buena Vista Pictures': 'Buena Vista Pictures',
r'UTV.*': 'UTV Motion Pictures',
r'United Artists.*': 'United Artists',
r'Universal.*': 'Universal Pictures',
r'Paramount.*': 'Paramount Pictures',
r'Orion.*': 'Orion Pictures',
r'Newmarket Film.*': 'Newmarket Film Group',
r'^United Film Distribution.*':'United Film Distribution Company',
r'^Cannon.*':'Cannon Films',
r'^Group 1.*':'Group 1',
r'^UN': 'Universal Pictures',
r'^Millenn?ium En.*': 'Millennium Entertainment',
}
}
rated_df.replace(replacements, regex=True, inplace=True)
rated_df.Production.nunique()
1207
rated_df.Production.value_counts()[:25]
Warner Brothers 1416
20th Century Fox 1103
Paramount Pictures 947
MGM 937
Universal Pictures 726
Sony Pictures 680
United Artists 395
Columbia Pictures 376
The Criterion Collection 243
MCA Universal 223
RKO Pictures 200
Buena Vista Pictures 193
Disney 165
Miramax Films 163
Lionsgate Films 149
New Line Cinema 147
VCI Entertainment 93
Republic Pictures 74
American International Pictures 72
The Weinstein Co. 71
DreamWorks 70
HBO 69
Anchor Bay Films 68
Orion Pictures 62
Focus Features 60
Name: Production, dtype: int64
rated_df.Production.isnull().sum()
3158
rated_df['Production'][rated_df['Title'] == 'Mad Max'] = 'Kennedy Miller Productions'
rated_df['Production'][rated_df['Title'] == 'The Night Porter'] = 'Lotar Film Productions'
Grab month as feature
rated_df['Month'] = rated_df.loc[:,"Release_Date"].apply(lambda x: x.month)
Grab awards won
def awards(string):
wins = re.compile(r"\d\d?")
#awards = []
ow = 0
on = 0
w = 0
n = 0
try:
listed = string.split('.')
for l in listed:
if 'Oscar' in l and l[0] == 'W':
ow = wins.findall(l)[0]
elif 'Oscar' in l and l[0] == 'N':
on = wins.findall(l)[0]
elif 'win' in l and 'nomination' in l:
w = wins.findall(l)[0]
n = wins.findall(l)[1]
elif 'nomination' in l and 'win' not in l:
n = wins.findall(l)[0]
else:
None
except:
None
return [ow,on,w,n]
rated_df['Awards_'] = rated_df['Awards'].apply(awards)
rated_df['Oscar_wins'] = rated_df['Awards_'].apply(lambda x: x[0])
rated_df['Oscar_noms'] = rated_df['Awards_'].apply(lambda x: x[1])
rated_df['Award_wins'] = rated_df['Awards_'].apply(lambda x: x[2])
rated_df['Award_noms'] = rated_df['Awards_'].apply(lambda x: x[3])
rated_df.drop(['Awards','Awards_'], axis=1, inplace=True)
Clean Runtime
def runtime(string):
ints = re.compile(r"\d\d?\d?")
try:
if 'h' in string and 'min' in string:
run = int(ints.findall(string)[0])*60 + int(ints.findall(string)[1])
elif 'h' in string:
run = int(ints.findall(string)[0])*60
elif 'min' in string:
run = int(ints.findall(string)[0])
else:
run = np.nan
except:
run = np.nan
return run
rated_df['RunTime'] = rated_df['Runtime'].apply(runtime)
rated_df.drop(['Runtime'], axis=1, inplace=True)
rated_df['RunTime'].isnull().sum()
481
# Impute missing Runtimes with median for year
rated_df['RunTime'].fillna(rated_df.groupby(['Year'])['RunTime'].transform("median"), inplace=True)
rated_df['RunTime'].isnull().sum()
0
Break out genres
def genre_1(string):
clean_list = []
try:
listy = string.split(',')
for l in listy:
clean = l.strip()
clean_list.append(clean)
return clean_list[0]
except:
return 'None'
rated_df['genre_1'] = rated_df["Genre"].apply(genre_1)
def genre_2(string):
clean_list = []
try:
listy = string.split(',')
for l in listy:
clean = l.strip()
clean_list.append(clean)
return clean_list[1]
except:
return 'None'
rated_df['genre_2'] = rated_df["Genre"].apply(genre_2)
def genre_3(string):
clean_list = []
try:
listy = string.split(',')
for l in listy:
clean = l.strip()
clean_list.append(clean)
return clean_list[2]
except:
return 'None'
rated_df['genre_3'] = rated_df["Genre"].apply(genre_3)
rated_df['genre_1'].unique()
array([u'Action', u'Adventure', u'Drama', u'Comedy', u'Crime', u'Western',
u'Animation', u'Romance', u'Mystery', u'Biography', u'Horror',
u'Family', u'War', u'Musical', u'Fantasy', u'Thriller', u'Sci-Fi',
'None', u'Short', u'Film-Noir', u'Music', u'History'], dtype=object)
rated_df['genre_1'].nunique()
22
genre_1 = rated_df['genre_1'].unique()
# Dummy genre
for genre in genre_1:
if genre in rated_df['genre_1']:
rated_df[genre] = 1
else:
rated_df[genre] = 0
Check Director Feature for duplicates
rated_df.Director.nunique()
4779
rated_df.Director.value_counts()[:20]
Michael Curtiz 78
John Ford 75
Raoul Walsh 58
Cecil B. DeMille 55
Alfred Hitchcock 53
Henry Hathaway 46
William A. Wellman 45
Richard Thorpe 43
Fritz Lang 43
King Vidor 40
D.W. Griffith 39
Woody Allen 39
George Cukor 39
Clarence Brown 38
Norman Taurog 37
Ernst Lubitsch 37
Mervyn LeRoy 36
Frank Borzage 35
Henry King 34
Howard Hawks 34
Name: Director, dtype: int64
choices_d = set(rated_df['Director'])
process.extract('Lana Wachowski', choices_d, limit=15)
[(u'Lana Wachowski, Lilly Wachowski', 90),
(u'Tom Tykwer, Lana Wachowski, Lilly Wachowski', 90),
(nan, 60),
(u'Alan Cohn', 60),
(u'Alan White', 58),
(u'Andrea Bianchi', 57),
(u'Andy Warhol', 56),
(u'Alan Rafkin', 56),
(u'Andrzej Zulawski', 53),
(u'Andrey Konchalovskiy', 53),
(u'Jack Delano', 53),
(u'Shane Meadows', 52),
(u'Lyndall Hobbs', 52),
(u'Susanna White', 52),
(u'Ngai Choi Lam', 52)]
Combine a few common teams
rated_df['Director'] = rated_df['Director'].str.replace('Ethan Coen, Joel Coen', 'Joel Coen, Ethan Coen')
rated_df['Director'] = rated_df['Director'].str.replace('Joel Coen, Ethan Coen', 'Joel & Ethan Coen')
rated_df['Director'] = rated_df['Director'].str.replace('Bobby Farrelly, Peter Farrelly', 'Peter Farrelly, Bobby Farrelly')
rated_df['Director'] = rated_df['Director'].str.replace('Peter Farrelly, Bobby Farrelly', 'Bobby & Peter Farrelly')
rated_df['Director'] = rated_df['Director'].str.replace('Michael Powell, Emeric Pressburger', 'Michael Powell & Emeric Pressburger')
rated_df['Director'] = rated_df['Director'].str.replace('Lana Wachowski, Lilly Wachowski', "The Wachowski's")
# Define a function to grab to first Director for each feature
def director(string):
clean_list = []
try:
listy = string.split(',')
for l in listy:
clean = l.strip()
clean_list.append(clean)
return clean_list[0]
except:
return 'Unknown'
rated_df['Director_1'] = rated_df['Director'].apply(director)
rated_df['Director_1'].nunique()
4161
rated_df['Director_1'].isnull().sum()
0
rated_df['Director_1'] = rated_df['Director_1'].fillna('Unknown')
rated_df['Director_1'].isnull().sum()
0
director_40 = rated_df['Director_1'].value_counts().head(40)
director_40 = pd.DataFrame(director_40)
director_40.reset_index(inplace=True)
director_40.columns = ['Director_1', 'Value']
directors = rated_df[["Director_1", "imdbRating"]].groupby(['Director_1'], \
as_index=False).mean()
top_directors = rated_df[["Director_1", "imdbRating"]].groupby(['Director_1'], \
as_index=False).mean().sort_values('imdbRating', ascending=False)
director_info = pd.merge(director_40, directors, how='left')
director_info = director_info.sort_values('imdbRating', ascending=False)
director_info.plot('Director_1', 'imdbRating', kind='bar', figsize=(10,7), legend=False, xticks=None,\
title = 'Average Rating for 40 most prolific Directors', ylim=(0,10), colormap='Paired')
<matplotlib.axes._subplots.AxesSubplot at 0x34637e990>
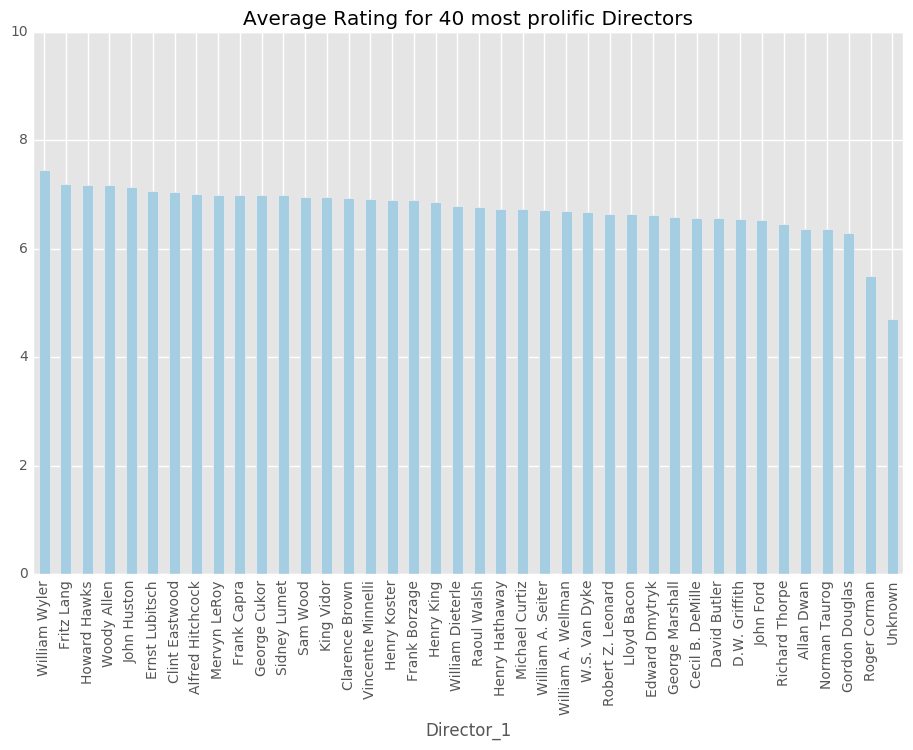
director_count = rated_df['Director_1'].value_counts()
director_count = pd.DataFrame(director_count)
director_count.reset_index(inplace=True)
director_count.columns = ['Director_1', 'Value']
director_5 = director_count[director_count.Value > 5]
director_5.head()
| Director_1 | Value | |
|---|---|---|
| 0 | Michael Curtiz | 84 |
| 1 | John Ford | 82 |
| 2 | Raoul Walsh | 60 |
| 3 | Cecil B. DeMille | 56 |
| 4 | Alfred Hitchcock | 53 |
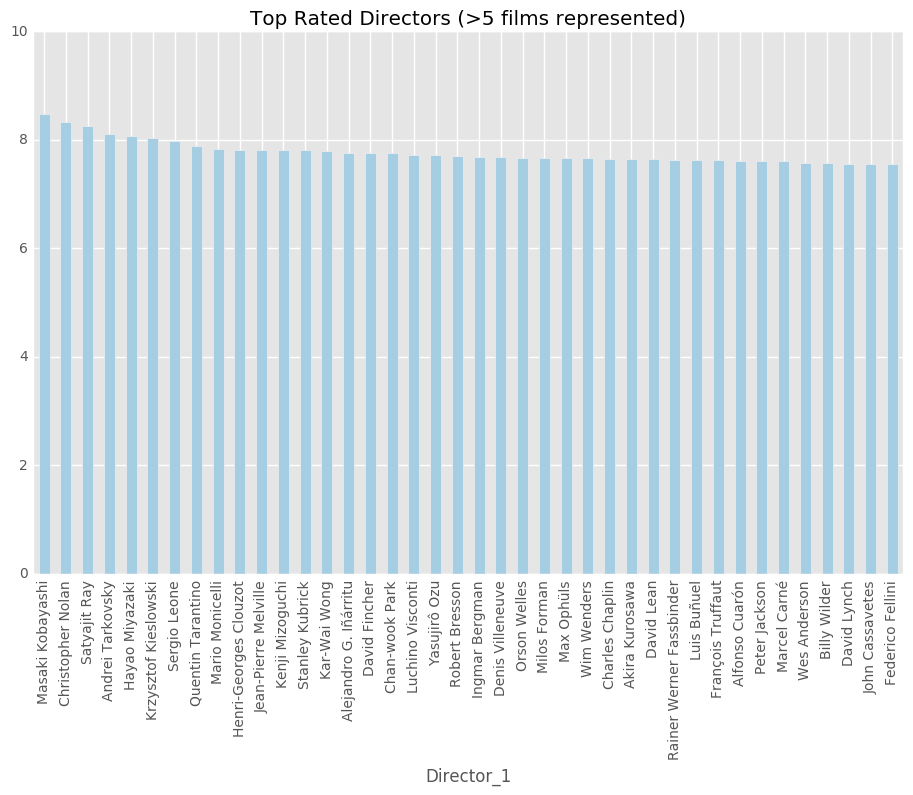
director_5_rating = pd.merge(director_5, top_directors, how='left')
director_5_rating = director_5_rating.sort_values('imdbRating', ascending=False)
director_5_rating = director_5_rating.head(40)
director_5_rating
| Director_1 | Value | imdbRating | |
|---|---|---|---|
| 577 | Masaki Kobayashi | 6 | 8.483333 |
| 375 | Christopher Nolan | 9 | 8.333333 |
| 645 | Satyajit Ray | 6 | 8.250000 |
| 441 | Andrei Tarkovsky | 8 | 8.100000 |
| 357 | Hayao Miyazaki | 10 | 8.080000 |
| 547 | Krzysztof Kieslowski | 7 | 8.028571 |
| 533 | Sergio Leone | 7 | 7.971429 |
| 275 | Quentin Tarantino | 11 | 7.881818 |
| 656 | Mario Monicelli | 6 | 7.833333 |
| 602 | Henri-Georges Clouzot | 6 | 7.816667 |
| 318 | Jean-Pierre Melville | 10 | 7.810000 |
| 286 | Kenji Mizoguchi | 11 | 7.809091 |
| 228 | Stanley Kubrick | 13 | 7.807692 |
| 610 | Kar-Wai Wong | 6 | 7.800000 |
| 587 | Alejandro G. Iñárritu | 6 | 7.766667 |
| 351 | David Fincher | 10 | 7.750000 |
| 629 | Chan-wook Park | 6 | 7.750000 |
| 196 | Luchino Visconti | 14 | 7.721429 |
| 91 | Yasujirô Ozu | 20 | 7.715000 |
| 315 | Robert Bresson | 11 | 7.709091 |
| 59 | Ingmar Bergman | 25 | 7.688000 |
| 615 | Denis Villeneuve | 6 | 7.683333 |
| 296 | Orson Welles | 11 | 7.672727 |
| 412 | Milos Forman | 9 | 7.666667 |
| 460 | Max Ophüls | 8 | 7.662500 |
| 542 | Wim Wenders | 7 | 7.657143 |
| 141 | Charles Chaplin | 17 | 7.652941 |
| 44 | Akira Kurosawa | 30 | 7.646667 |
| 168 | David Lean | 15 | 7.640000 |
| 448 | Rainer Werner Fassbinder | 8 | 7.625000 |
| 84 | Luis Buñuel | 21 | 7.623810 |
| 183 | François Truffaut | 15 | 7.620000 |
| 582 | Alfonso Cuarón | 6 | 7.616667 |
| 227 | Peter Jackson | 13 | 7.615385 |
| 411 | Marcel Carné | 9 | 7.611111 |
| 449 | Wes Anderson | 8 | 7.575000 |
| 61 | Billy Wilder | 25 | 7.568000 |
| 293 | David Lynch | 11 | 7.563636 |
| 321 | John Cassavetes | 10 | 7.560000 |
| 175 | Federico Fellini | 15 | 7.560000 |
director_5_rating.plot('Director_1', 'imdbRating', kind='bar', figsize=(10,7), legend=False, xticks=None,\
title = 'Top Rated Directors (>5 films represented)', ylim=(0,10), colormap='Paired')
<matplotlib.axes._subplots.AxesSubplot at 0x3511a8390>
directors_5up = director_5['Director_1']
len(directors_5up)
658
# Dummy important directors
# Since director seams so important we will use the 658 for dummies
for dirc in directors_5up:
if dirc in rated_df['Director_1']:
rated_df[dirc] = 1
else:
rated_df[dirc] = 0
Language
rated_df['Language'].nunique()
959
rated_df['Language_main'] = rated_df['Language'].apply(director)
rated_df['Language_main'].nunique()
58
rated_df['Language_main'].value_counts()[:20]
English 12439
Unknown 672
French 504
Italian 324
German 236
Japanese 186
Spanish 127
Swedish 63
Russian 61
Hindi 56
Mandarin 33
Cantonese 32
Danish 26
Polish 15
Czech 15
Korean 15
Turkish 14
Portuguese 12
Dutch 9
Greek 8
Name: Language_main, dtype: int64
rated_df['Language_main'] = rated_df['Language_main'].str.replace('Unknown','English')
rated_df['Language_main'].value_counts()[:20]
English 13111
French 504
Italian 324
German 236
Japanese 186
Spanish 127
Swedish 63
Russian 61
Hindi 56
Mandarin 33
Cantonese 32
Danish 26
Korean 15
Czech 15
Polish 15
Turkish 14
Portuguese 12
Dutch 9
Hungarian 8
Greek 8
Name: Language_main, dtype: int64
rated_df['Language_main'].isnull().sum()
0
Rating
rated_df['Rated'] = rated_df['Rated'].str.lower()
rated_df['Rated'].unique()
array([u'approved', u'pg', u'r', u'pg-13', nan, u'g', u'passed', u'tv-g',
u'not rated', u'unrated', u'm', u'tv-pg', u'gp', u'x', u'nc-17',
u'tv-ma', u'tv-14'], dtype=object)
rated_df['Rated'] = rated_df['Rated'].fillna('None')
rated_df['Rated'].isnull().sum()
0
rating_dum = rated_df['Rated'].unique()
# Dummy rating
for rate in rating_dum:
if rate in rated_df['Rated']:
rated_df[rate+' Rated'] = 1
else:
rated_df[rate+' Rated'] = 0
rated_df.columns
Index([ u'Actors', u'BoxOffice', u'Country',
u'Director', u'Genre', u'Language',
u'Metascore', u'Plot', u'Production',
u'Rated',
...
u'tv-g Rated', u'not rated Rated', u'unrated Rated',
u'm Rated', u'tv-pg Rated', u'gp Rated',
u'x Rated', u'nc-17 Rated', u'tv-ma Rated',
u'tv-14 Rated'],
dtype='object', length=726)
Country
rated_df['Country'].nunique()
766
rated_df['Country_Main'] = rated_df['Country'].apply(director)
rated_df['Country_Main'].nunique()
65
rated_df['Country_Main'].value_counts()[:20]
USA 10505
UK 1566
France 653
Italy 437
Germany 270
Japan 208
Canada 154
Australia 127
Spain 105
Sweden 95
West Germany 76
Soviet Union 74
India 73
Denmark 63
Mexico 61
Hong Kong 54
Russia 28
Ireland 26
Unknown 24
Austria 23
Name: Country_Main, dtype: int64
rated_df['Country_Main'] = rated_df['Country_Main'].str.replace('Unknown','USA')
rated_df['Country_Main'].isnull().sum()
0
country_values = rated_df['Country_Main'].value_counts()
country_values = pd.DataFrame(country_values)
country_values.reset_index(inplace=True)
country_values.columns = ['Country_Main', 'Values']
country_values.head()
| Country_Main | Values | |
|---|---|---|
| 0 | USA | 10529 |
| 1 | UK | 1566 |
| 2 | France | 653 |
| 3 | Italy | 437 |
| 4 | Germany | 270 |
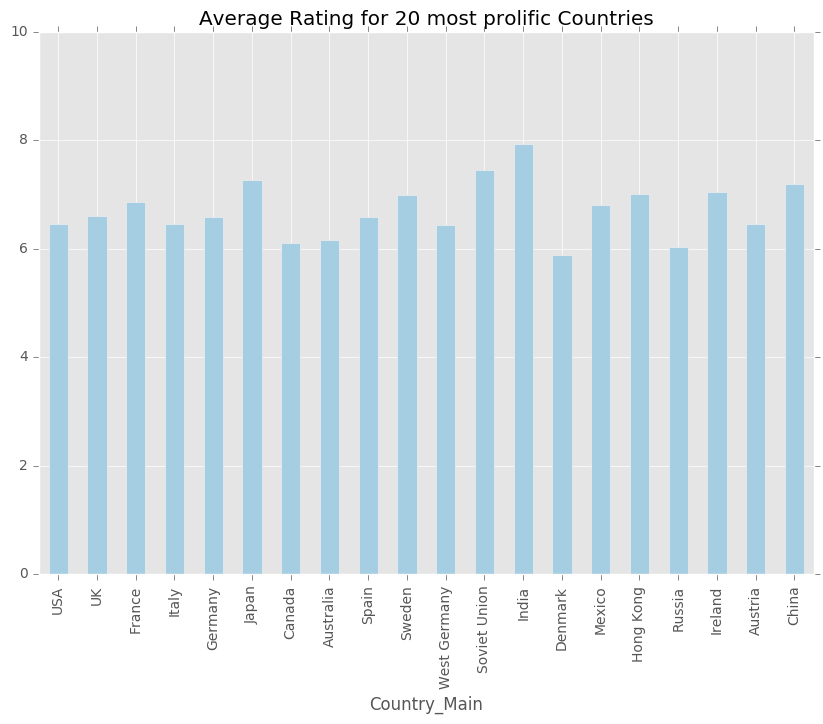
Top_countries = rated_df[["Country_Main", "imdbRating"]].groupby(['Country_Main'], as_index=False).mean()
country_info = pd.merge(Top_countries, country_values, how='left')
country_20 = country_info.sort_values('Values', ascending=False).head(20)
country_20.plot('Country_Main', 'imdbRating', kind='bar', figsize=(10,7), legend=False, xticks=None,\
title = 'Average Rating for 20 most prolific Countries', ylim=(0,10), colormap='Paired')
<matplotlib.axes._subplots.AxesSubplot at 0x10e51f790>
country_dummy = rated_df['Country_Main'].value_counts()
country_dummy = pd.DataFrame(country_dummy)
country_dummy = country_dummy[country_dummy.Country_Main > 5]
country_index = country_dummy.index
country_index
Index([u'USA', u'UK', u'France', u'Italy', u'Germany', u'Japan', u'Canada',
u'Australia', u'Spain', u'Sweden', u'West Germany', u'Soviet Union',
u'India', u'Denmark', u'Mexico', u'Hong Kong', u'Russia', u'Ireland',
u'Austria', u'China', u'New Zealand', u'Czechoslovakia', u'Poland',
u'South Korea', u'Switzerland', u'Netherlands', u'Hungary', u'Turkey',
u'Argentina', u'Greece', u'Brazil', u'Belgium', u'Norway',
u'South Africa', u'Yugoslavia', u'Taiwan', u'Finland', u'Portugal',
u'Iran', u'Philippines'],
dtype='object')
# Dummy country
for country in country_index:
if country in rated_df['Country_Main']:
rated_df[country] = 1
else:
rated_df[country] = 0
Production Company
rated_df['Production'].nunique()
1208
rated_df['Production'].isnull().sum()
3158
rated_df['Production'] = rated_df['Production'].fillna('None')
rated_df['Production'].isnull().sum()
0
production = pd.DataFrame(rated_df['Production'].value_counts()[:100]).T
production.drop('None', axis=1, inplace=True)
production.head()
| Warner Brothers | 20th Century Fox | Paramount Pictures | MGM | Universal Pictures | Sony Pictures | United Artists | Columbia Pictures | The Criterion Collection | MCA Universal | ... | Madacy Entertainment | Lorimar Home Video | Film Chest | Jensen Farley Pictures | Independent International Pictures | Tartan Films | Associated Film Distribution | Independent Pictures | Rogue Pictures | Drafthouse Films | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Production | 1416 | 1103 | 947 | 937 | 726 | 680 | 395 | 376 | 243 | 223 | ... | 8 | 8 | 8 | 7 | 7 | 7 | 7 | 7 | 7 | 7 |
1 rows × 99 columns
top_production = production.columns
for pro in top_production:
if pro in rated_df['Production']:
rated_df['P_'+pro] = 1
else:
rated_df['P_'+pro] = 0
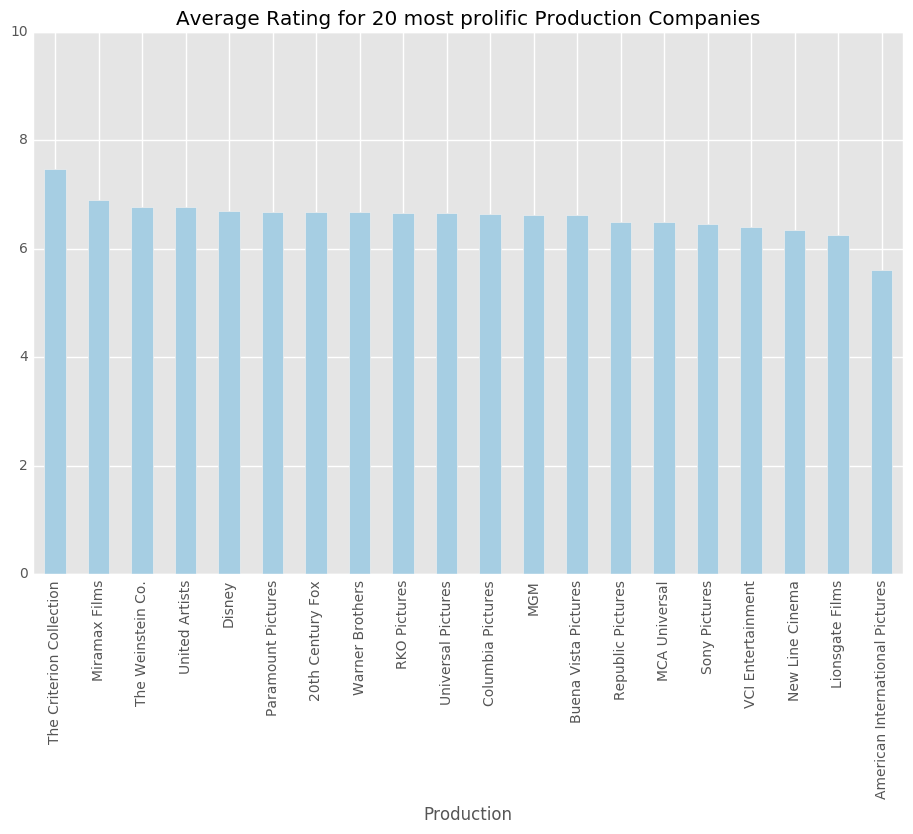
production_20 = pd.DataFrame(top_production[:20])
production_20.columns = ['Production']
production_ratings = rated_df[["Production", "imdbRating"]].groupby(['Production'], as_index=False).mean()
production_ratings_20 = pd.merge(production_20, production_ratings, how='left')
production_sort = production_ratings_20.sort_values('imdbRating', ascending=False)
production_sort.plot('Production', 'imdbRating', kind='bar', figsize=(10,7), legend=False, xticks=None,\
title = 'Average Rating for 20 most prolific Production Companies', ylim=(0,10), colormap='Paired')
<matplotlib.axes._subplots.AxesSubplot at 0x3344933d0>
Actors
rated_df['Actors'].describe()
count 14876
unique 14790
top Roy Rogers, Trigger, George 'Gabby' Hayes, Dal...
freq 6
Name: Actors, dtype: object
rated_df['Actors'].isnull().sum()
61
rated_df['Actors'].fillna(value='None', inplace=True)
rated_df['Actors'].isnull().sum()
0
# Countvectorize actors
def grams_per_comma(string):
for ln in string.split(','):
terms = re.findall(r'\w{2,}', ln)
for gram in zip(terms, terms[1:]):
yield '%s %s' % gram
from sklearn.feature_extraction.text import CountVectorizer
cvec = CountVectorizer(analyzer=grams_per_comma, ngram_range=(3, 3), max_features=100)
cvec.fit(rated_df['Actors'])
CountVectorizer(analyzer=<function grams_per_comma at 0x10e580a28>,
binary=False, decode_error=u'strict', dtype=<type 'numpy.int64'>,
encoding=u'utf-8', input=u'content', lowercase=True, max_df=1.0,
max_features=100, min_df=1, ngram_range=(3, 3), preprocessor=None,
stop_words=None, strip_accents=None,
token_pattern=u'(?u)\\b\\w\\w+\\b', tokenizer=None,
vocabulary=None)
actors_df = pd.DataFrame(cvec.transform(rated_df['Actors']).todense(),
columns=cvec.get_feature_names())
actors = actors_df.transpose().sort_values(0, ascending=False).transpose()
print actors.shape
actors.head()
(14937, 100)
| Adolphe Menjou | Lionel Barrymore | Nicolas Cage | Myrna Loy | Michael Caine | Meryl Streep | Melvyn Douglas | Maureen Hara | Mary Pickford | Marlon Brando | ... | Fred MacMurray | Frank Sinatra | Frank Morgan | Franchot Tone | Errol Flynn | Elizabeth Taylor | Edward Robinson | Douglas Fairbanks | Doris Day | William Powell | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 100 columns
actors_columns = []
for i in actors.columns:
name = i+'_Actor'
actors_columns.append(name)
actors.columns = actors_columns
actors.head(1)
| Adolphe Menjou_Actor | Lionel Barrymore_Actor | Nicolas Cage_Actor | Myrna Loy_Actor | Michael Caine_Actor | Meryl Streep_Actor | Melvyn Douglas_Actor | Maureen Hara_Actor | Mary Pickford_Actor | Marlon Brando_Actor | ... | Fred MacMurray_Actor | Frank Sinatra_Actor | Frank Morgan_Actor | Franchot Tone_Actor | Errol Flynn_Actor | Elizabeth Taylor_Actor | Edward Robinson_Actor | Douglas Fairbanks_Actor | Doris Day_Actor | William Powell_Actor | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
1 rows × 100 columns
merge_df = rated_df.merge(actors, how='left', left_index=True, right_index=True)
print merge_df.shape
merge_df.head(1)
(14937, 966)
| Actors | BoxOffice | Country | Director | Genre | Language | Metascore | Plot | Production | Rated | ... | Fred MacMurray_Actor | Frank Sinatra_Actor | Frank Morgan_Actor | Franchot Tone_Actor | Errol Flynn_Actor | Elizabeth Taylor_Actor | Edward Robinson_Actor | Douglas Fairbanks_Actor | Doris Day_Actor | William Powell_Actor | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | John Agar, Joyce Meadows, Robert Fuller, Thoma... | NaN | USA | Nathan Juran | Action, Adventure, Horror | English | NaN | Gor, a powerful criminal brain from the planet... | Howco International Pictures | approved | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
1 rows × 966 columns
Plot
rated_df['Plot'].fillna('None',inplace=True)
cvec = CountVectorizer(stop_words='english', max_features=40)
cvec.fit(rated_df['Plot'])
CountVectorizer(analyzer=u'word', binary=False, decode_error=u'strict',
dtype=<type 'numpy.int64'>, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=40, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words='english',
strip_accents=None, token_pattern=u'(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
plot_tdf = pd.DataFrame(cvec.transform(rated_df['Plot']).todense(),
columns=cvec.get_feature_names())
plot_feats = plot_tdf.transpose().sort_values(0, ascending=False).transpose().head()
plot_feats.head()
| world | american | time | new | old | school | small | son | story | takes | ... | gets | love | girl | group | help | home | husband | life | lives | young | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
5 rows × 40 columns
plot_columns = []
for i in plot_feats.columns:
name = 'Plot_'+i
plot_columns.append(name)
plot_feats.columns = plot_columns
plot_feats.head()
| Plot_world | Plot_american | Plot_time | Plot_new | Plot_old | Plot_school | Plot_small | Plot_son | Plot_story | Plot_takes | ... | Plot_gets | Plot_love | Plot_girl | Plot_group | Plot_help | Plot_home | Plot_husband | Plot_life | Plot_lives | Plot_young | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
5 rows × 40 columns
merge_df = merge_df.merge(plot_feats, how='left', left_index=True, right_index=True)
print merge_df.shape
merge_df.head(1)
(14937, 1006)
| Actors | BoxOffice | Country | Director | Genre | Language | Metascore | Plot | Production | Rated | ... | Plot_gets | Plot_love | Plot_girl | Plot_group | Plot_help | Plot_home | Plot_husband | Plot_life | Plot_lives | Plot_young | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | John Agar, Joyce Meadows, Robert Fuller, Thoma... | NaN | USA | Nathan Juran | Action, Adventure, Horror | English | NaN | Gor, a powerful criminal brain from the planet... | Howco International Pictures | approved | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
1 rows × 1006 columns
Title
cvec_t = CountVectorizer(stop_words='english', max_features=40)
cvec_t.fit(rated_df['Title'])
CountVectorizer(analyzer=u'word', binary=False, decode_error=u'strict',
dtype=<type 'numpy.int64'>, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=40, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words='english',
strip_accents=None, token_pattern=u'(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
title_df = pd.DataFrame(cvec_t.transform(rated_df['Title']).todense(),
columns=cvec_t.get_feature_names())
title = title_df.transpose().sort_values(0, ascending=False).transpose()
print title.shape
title.head()
(14937, 40)
| adventures | american | little | love | man | men | mr | new | night | red | ... | death | king | devil | die | girl | girls | great | house | ii | young | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 40 columns
title_columns = []
for i in title.columns:
name = 'Title_'+i
title_columns.append(name)
title.columns = title_columns
title.head()
| Title_adventures | Title_american | Title_little | Title_love | Title_man | Title_men | Title_mr | Title_new | Title_night | Title_red | ... | Title_death | Title_king | Title_devil | Title_die | Title_girl | Title_girls | Title_great | Title_house | Title_ii | Title_young | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 40 columns
merge_df = merge_df.merge(title, how='left', left_index=True, right_index=True)
print merge_df.shape
merge_df.head(1)
(14937, 1046)
| Actors | BoxOffice | Country | Director | Genre | Language | Metascore | Plot | Production | Rated | ... | Title_death | Title_king | Title_devil | Title_die | Title_girl | Title_girls | Title_great | Title_house | Title_ii | Title_young | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | John Agar, Joyce Meadows, Robert Fuller, Thoma... | NaN | USA | Nathan Juran | Action, Adventure, Horror | English | NaN | Gor, a powerful criminal brain from the planet... | Howco International Pictures | approved | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
1 rows × 1046 columns
Producers
producers = pd.read_pickle('producer_df.pkl')
# Define a function to grab to first Director for each feature
def producer(listy):
try:
return listy[0]
except:
return 'None'
producers['Producer_1'] = producers['Producers'].apply(producer)
producer_clean = producers.drop('Producers', axis=1)
producer_clean.head()
| imdbID | Producer_1 | |
|---|---|---|
| 0 | tt0437222 | None |
| 1 | tt0050210 | Jacques R. Marquette |
| 2 | tt0030725 | George M. Merrick |
| 3 | tt0050212 | Sam Spiegel |
| 4 | tt0381681 | Isabelle Coulet |
top_producers = producer_clean['Producer_1'].value_counts()[:100]
top_producers = pd.DataFrame(top_producers)
top_producers.reset_index(inplace=True)
top_producers = top_producers.iloc[1:,:]
top_producers_list = top_producers['index']
top_producers_list
1 Samuel Goldwyn
2 Pandro S. Berman
3 Cecil B. DeMille
4 Samuel Z. Arkoff
5 Henry Blanke
6 Bruce Berman
7 Michael Balcon
8 Tim Bevan
9 Hal B. Wallis
10 Samuel Bischoff
11 Gary Barber
12 Hunt Stromberg
13 Joe Pasternak
14 Dino De Laurentiis
15 William LeBaron
16 Jesse L. Lasky
17 Erich Pommer
18 D.W. Griffith
19 Yoram Globus
20 Harry Joe Brown
21 Darryl F. Zanuck
22 Thomas H. Ince
23 Roger Corman
24 Jerry Wald
25 Arthur Freed
26 William Fox
27 Sol C. Siegel
28 David O. Selznick
29 Robert Arthur
30 Barry Bernardi
...
70 William Jacobs
71 Alexander Korda
72 Sam Zimbalist
73 David Brown
74 Francis Ford Coppola
75 Jack J. Gross
76 Walter Mirisch
77 John Stone
78 Stanley Kramer
79 Robert Chartoff
80 Jason Blum
81 Samuel G. Engel
82 John W. Considine Jr.
83 Richard Brener
84 Don Carmody
85 Robert Fellows
86 Joseph M. Schenck
87 Joseph L. Mankiewicz
88 Otto Preminger
89 Ashok Amritraj
90 Albert R. Broccoli
91 Paul Davidson
92 Edward Small
93 Louis D. Lighton
94 Raymond Griffith
95 Luc Besson
96 Nat Levine
97 Sol Lesser
98 William Goetz
99 Raymond Hakim
Name: index, dtype: object
for duce in top_producers_list:
if duce in producer_clean['Producer_1']:
producer_clean['Producer_'+duce] = 1
else:
producer_clean['Producer_'+duce] = 0
producer_clean.head()
| imdbID | Producer_1 | Producer_Samuel Goldwyn | Producer_Pandro S. Berman | Producer_Cecil B. DeMille | Producer_Samuel Z. Arkoff | Producer_Henry Blanke | Producer_Bruce Berman | Producer_Michael Balcon | Producer_Tim Bevan | ... | Producer_Albert R. Broccoli | Producer_Paul Davidson | Producer_Edward Small | Producer_Louis D. Lighton | Producer_Raymond Griffith | Producer_Luc Besson | Producer_Nat Levine | Producer_Sol Lesser | Producer_William Goetz | Producer_Raymond Hakim | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | tt0437222 | None | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | tt0050210 | Jacques R. Marquette | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | tt0030725 | George M. Merrick | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | tt0050212 | Sam Spiegel | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | tt0381681 | Isabelle Coulet | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 101 columns
# Merge producer_1
merge_df = pd.merge(merge_df, producer_clean, how='left')
print merge_df.shape
merge_df.head(1)
(14937, 1146)
| Actors | BoxOffice | Country | Director | Genre | Language | Metascore | Plot | Production | Rated | ... | Producer_Albert R. Broccoli | Producer_Paul Davidson | Producer_Edward Small | Producer_Louis D. Lighton | Producer_Raymond Griffith | Producer_Luc Besson | Producer_Nat Levine | Producer_Sol Lesser | Producer_William Goetz | Producer_Raymond Hakim | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | John Agar, Joyce Meadows, Robert Fuller, Thoma... | NaN | USA | Nathan Juran | Action, Adventure, Horror | English | NaN | Gor, a powerful criminal brain from the planet... | Howco International Pictures | approved | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
1 rows × 1146 columns
Box Office
gross = pd.read_pickle('gross_perf.pkl')
gross.reset_index(drop=True, inplace=True)
gross.head()
| imdbID | Budget | Gross | performance | |
|---|---|---|---|---|
| 0 | tt0050210 | 58000.0 | NaN | NaN |
| 1 | tt0050212 | 3000000.0 | 5668000.0 | 0.889333 |
| 2 | tt0381681 | 2700000.0 | 5792822.0 | 1.145490 |
| 3 | tt0472160 | 15000000.0 | 10011274.0 | -0.332582 |
| 4 | tt0209475 | 35000000.0 | 94728529.0 | 1.706529 |
gross.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7701 entries, 0 to 7700
Data columns (total 4 columns):
imdbID 7701 non-null object
Budget 6069 non-null float64
Gross 6433 non-null float64
performance 4801 non-null float64
dtypes: float64(3), object(1)
memory usage: 240.7+ KB
# Only 4800 films with info for both gross and budget
# Performance is a measure of how well a film did in the box office in relation to its budget
# Will subset the data later and run another model using performance
merge_df.to_pickle('merged_cleaned.pkl')
merge_df.columns
Index([ u'Actors', u'BoxOffice',
u'Country', u'Director',
u'Genre', u'Language',
u'Metascore', u'Plot',
u'Production', u'Rated',
...
u'Producer_Albert R. Broccoli', u'Producer_Paul Davidson',
u'Producer_Edward Small', u'Producer_Louis D. Lighton',
u'Producer_Raymond Griffith', u'Producer_Luc Besson',
u'Producer_Nat Levine', u'Producer_Sol Lesser',
u'Producer_William Goetz', u'Producer_Raymond Hakim'],
dtype='object', length=1146)
drop = [u'Actors', u'BoxOffice', u'Country', u'Director',
u'Genre', u'Language', u'Metascore', u'Plot',
u'Production', 'Released', 'Title', 'Writer',
'Release_Date']
df = merge_df.drop(drop, axis=1)
# Fill votes with the mdeian for the rating
df.imdbVotes.fillna(df.groupby(["imdbRating"])["imdbVotes"].transform("median"), inplace=True)
# Fill month with the mode
df.Month.fillna(df.Month.mode()[0], inplace=True)
import seaborn as sns
# Create a list of quantitative data columns
quant = ['imdbRating',
'imdbVotes',
'Year',
'Month',
'RunTime']
quant
['imdbRating', 'imdbVotes', 'Year', 'Month', 'RunTime']
# Plot Histograms of numerical data columns
sns.set(rc={"figure.figsize": (8, 4)})
for i in quant:
sns.distplot(df[i])
plt.xlabel(i)
plt.ylabel('Count')
plt.show()
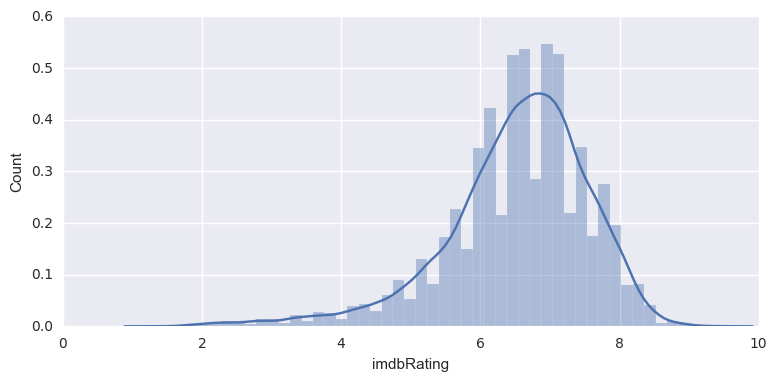
df['imdbRating'].describe(percentiles=[.25,.33,.66, .75])
count 14937.000000
mean 6.528560
std 1.041723
min 1.300000
25% 6.000000
33% 6.200000
50% 6.700000
66% 7.000000
75% 7.200000
max 9.500000
Name: imdbRating, dtype: float64
# Bin rating into high, mid, low (3,2,1)
rating_labels = []
for i in df['imdbRating']:
if i >= 7.2:
rate = 2
elif i >= 6.2:
rate = 1
else:
rate = 0
rating_labels.append(rate)
df['Rating_Labels'] = rating_labels
df.iloc[:,:15].head(1)
| Rated | Year | imdbID | imdbRating | imdbVotes | Month | Oscar_wins | Oscar_noms | Award_wins | Award_noms | RunTime | genre_1 | genre_2 | genre_3 | Action | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | approved | 1957 | tt0050210 | 5.3 | 1109.0 | 10.0 | 0 | 0 | 0 | 0 | 71.0 | Action | Adventure | Horror | 0 |
drop_for_sklearn = ['Rated', 'imdbID', 'imdbRating', 'genre_1', 'genre_2', 'genre_3',\
u'Director_1',u'Language_main',u'Country_Main', 'Producer_1',]
df.imdbVotes = df.imdbVotes.apply(int)
df.to_pickle('df.pkl')
df_1 = df.drop(drop_for_sklearn, axis=1)
df_1.columns
Index([ u'Year', u'imdbVotes',
u'Month', u'Oscar_wins',
u'Oscar_noms', u'Award_wins',
u'Award_noms', u'RunTime',
u'Action', u'Adventure',
...
u'Producer_Paul Davidson', u'Producer_Edward Small',
u'Producer_Louis D. Lighton', u'Producer_Raymond Griffith',
u'Producer_Luc Besson', u'Producer_Nat Levine',
u'Producer_Sol Lesser', u'Producer_William Goetz',
u'Producer_Raymond Hakim', u'Rating_Labels'],
dtype='object', length=1124)
df_1.to_pickle('df_1.pkl')
Models
dropped = ['Rating_Labels']
X = df_1.drop(dropped, axis=1)
y = df_1['Rating_Labels']
X.Oscar_wins.isnull().sum()
0
process.extract('Fox', choices, limit=15)
X = X.fillna(method='ffill')
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, BaggingClassifier
cv = StratifiedKFold(n_splits=3, random_state=21, shuffle=True)
dt = DecisionTreeClassifier()
bc = BaggingClassifier(dt)
rf = RandomForestClassifier(n_estimators=1000, class_weight='balanced')
xt = ExtraTreesClassifier(n_estimators=1000, class_weight='balanced')
def score(model, string):
s = cross_val_score(model, X, y, cv=cv)
print("{} Score:\t{:0.3} ± {:0.3}".format(string, s.mean().round(3), s.std().round(3)))
score(bc, 'Bagging')
Bagging Score: 0.588 ± 0.002
score(rf, 'Random')
Random Score: 0.614 ± 0.003
score(xt, 'Extra Trees')
Extra Trees Score: 0.58 ± 0.006
rf = RandomForestClassifier(n_estimators=1000, max_depth = 5, class_weight='balanced')
model = rf.fit(X, y)
# importances = rf.feature_importances_
# importances =pd.DataFrame(importances)
# importances.sort_values(0,ascending=False).head(20)
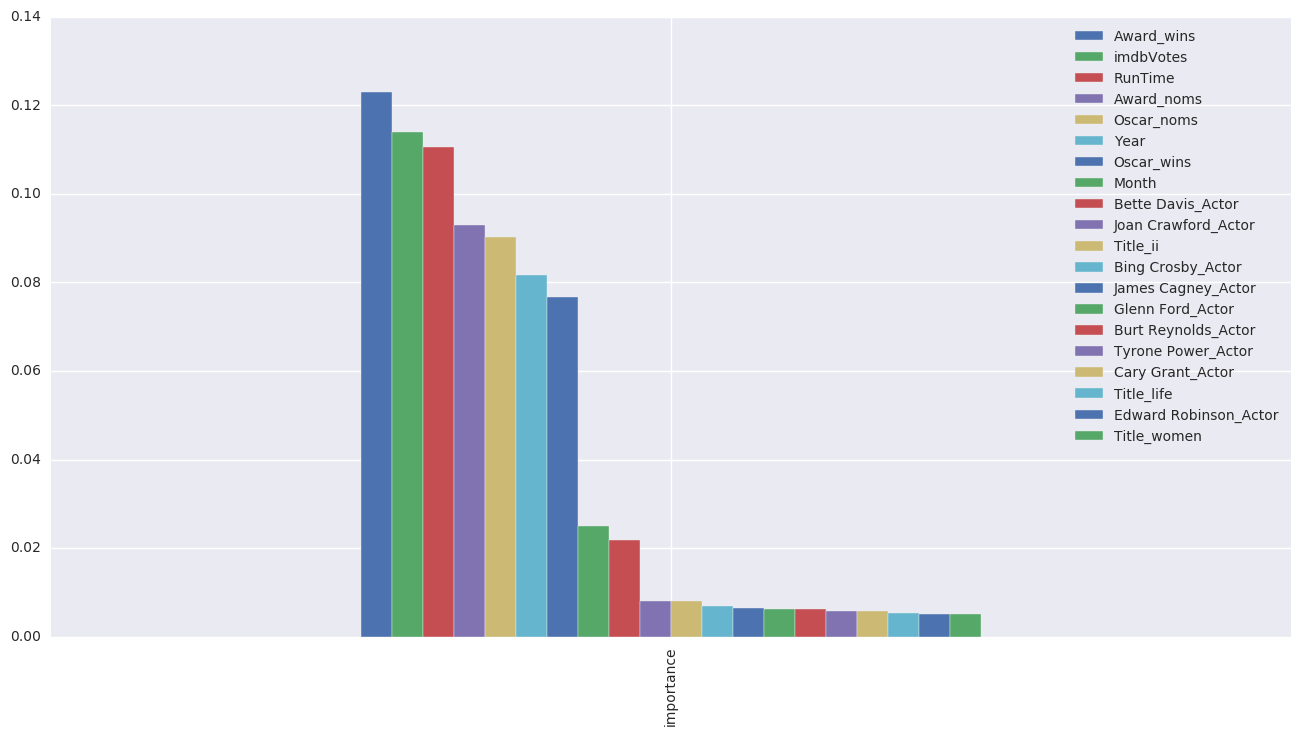
feature_importances = pd.DataFrame(rf.feature_importances_,
index = X.columns,
columns=['importance'])
importances = feature_importances.sort_values(by='importance', ascending=False).head(20).T
importances
| Award_wins | imdbVotes | RunTime | Award_noms | Oscar_noms | Year | Oscar_wins | Month | Bette Davis_Actor | Joan Crawford_Actor | Title_ii | Bing Crosby_Actor | James Cagney_Actor | Glenn Ford_Actor | Burt Reynolds_Actor | Tyrone Power_Actor | Cary Grant_Actor | Title_life | Edward Robinson_Actor | Title_women | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| importance | 0.123021 | 0.113878 | 0.110671 | 0.092955 | 0.090375 | 0.08169 | 0.076681 | 0.025117 | 0.021872 | 0.008043 | 0.008019 | 0.006951 | 0.006609 | 0.006228 | 0.00617 | 0.005883 | 0.005858 | 0.00532 | 0.005189 | 0.005147 |
fig, ax = plt.subplots(figsize=(16,8))
importances.plot(kind='bar', ax=ax)
<matplotlib.axes._subplots.AxesSubplot at 0x144d28f10>
pred = model.predict(X)
from sklearn.metrics import confusion_matrix, classification_report
# conf matrix
cm = confusion_matrix(y, pred)
cm = pd.DataFrame(cm, columns=["Predict Low Rating", "Predict Average Rating", "Predict High Rating"], \
index=["Low Rating", "Average Rating", "High Rating"] )
cm
| Predict Low Rating | Predict Average Rating | Predict High Rating | |
|---|---|---|---|
| Low Rating | 3664 | 178 | 562 |
| Average Rating | 3451 | 1123 | 1770 |
| High Rating | 1381 | 311 | 2497 |
print(classification_report(y, pred))
precision recall f1-score support
0 0.43 0.83 0.57 4404
1 0.70 0.18 0.28 6344
2 0.52 0.60 0.55 4189
avg / total 0.57 0.49 0.44 14937