
Measuring the Billboard Hot 100 of 2000
Introduction
This week we are looking at data from the Billboard Hot 100 of 2000. Our dataset represents the top performing tracks for the year 2000 based on Billboard’s metrics. It includes all of the tracks that peaked during the year 2000. Using Billboard’s chart data we can look for any indicators for what made a song do well.
Assumptions
Lets look at how Billboard compiles its Hot 100 list since many of our assumptions will be due to Billboard’s own metrics.
“Chart rankings are based on sales (physical and digital), radio play and online streaming.”
Also interesting to note is the way in which Billboard charts by genre, which is done by tracking audiences rather than grouping tracks by their recognized genre:
“What separates the charts is which stations and stores are used; each musical genre has a core audience or retail group. Each genre’s department at Billboard is headed up by a chart manager, who makes these determinations.”
In this excercise we will assume that the Billboard’s metrics for measuring tracks are a good measure of performance.
We are also assuming the labelling of our data is correct. Genre is a contentious issue, but since Billboard is our client in this case, we will trust their judgement here. (The data is mislabelled, but for the purposes of this project we will assume it is correct.)
Because Billboard determines genre rankings by tracking the expected audience rather than basing the genre on song characteristics, many songs crossover into multiple genre charts. For instance, a song may chart in the R&B chart as well as the Pop chart if it is popular in the metrics for both audiences. We will use this information to relabel tracks that fall into genres representing less than 1% of our data.
Some of our risks:
-
The data set is not very large and only contains data for one year. It would be difficult to maintain any correlations found here over further years.
-
Because we are not privy to Billboard’s metrics and our data is one step removed, it does not contain the level fineness used in ranking songs in the Hot 100. Therefore a song reaching the number one spot for three weeks in May may not have done as well as a song reaching the top spot for three weeks in June based on the underlying metrics, but we will have to treat them as equal here.
Exploring the data / Munging
We reformatted quite a bit of the data. Null values were set using np.nan. Empty week columns were dropped, as was the column for year as all tracks are from 2000.
Categorical series were checked for duplicates. The genre categories were relabelled to correct some duplicates and to group tracks from lesser represented genres into broader genres. The logic for this is that many songs - especially from underrepresented genres - can be considered crossover songs, charting in multiple genre categories.
The track length - ‘time’ - was reformatted from ‘mm.ss.ms AM’ into seconds. Additionally, to be able to calculate the number of weeks it took a song to peak, the date for entry into the chart and the date for peaking were both reformatted from a string in the format ‘Month Day, Year’ into a Datetime format.
The top ranking and number of weeks a track was in the charts were also pulled out of the data, and a song score was computed by summing the inverse rank over all weeks a song charted.
Some Initial Observations
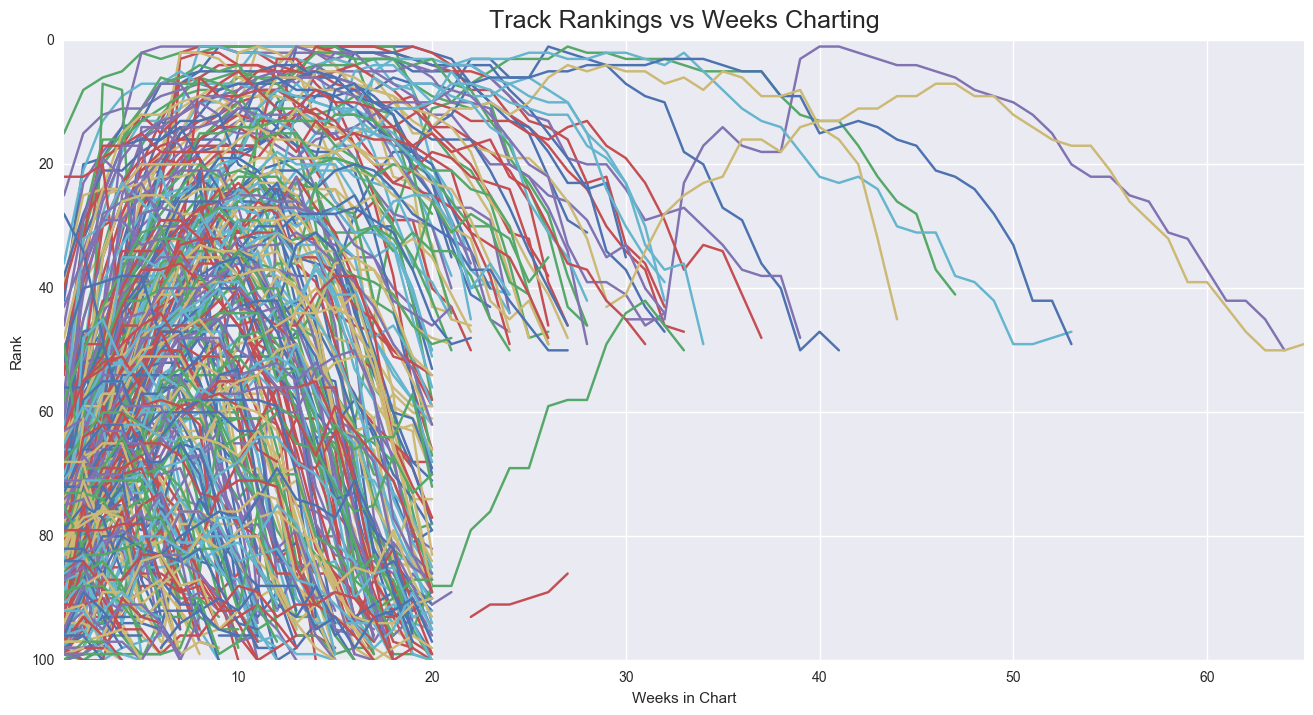
Some interesting quirks arose while exploring the data. Most racks in the Hot 100 fell of the charts after week 20. All of these tracks were ranked below the top 50 when they exited. Additionally, tracks that remained in the charts beyond 20 weeks all exited the chart in the top 50.
This ‘death zone’ beyond 20 weeks and under the top 40, leads me to speculate that there are some quirks in either the music industry or in the methods Billboatd uses to rank songs. For instance, this could represent the prevalence of top 40 radio airplay and Billboards us of airplay in their ranking methods.
There could be a 20 week airplay rotation for songs, with only those in the top 40 remaining in the charts beyond this point. This could represent an over reliance on airplay in determining the rankings in the Hot 100.
If we take a look at the genres we can see that rock songs are the most numerous in the charts in 2000, but Rock’n’roll tracks appear to perform much better.
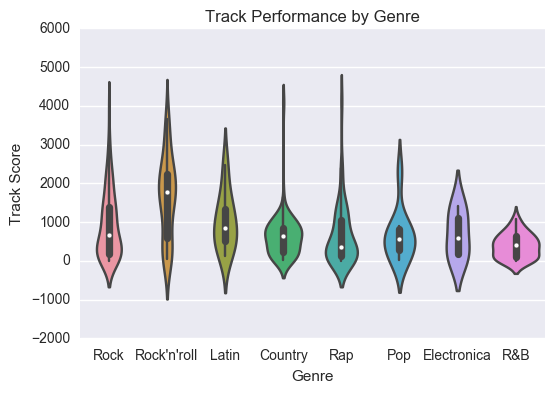
Rock’n’roll songs demonstrate a median song score of over 1600. That is almost 1200 points better than the median song score for all tracks.
Evaluations
This leads us to our first problem statement:
- Do certain genres perform better than others
To determine if the median score difference for Rock’n’roll songs is significant we will use the shuffle method. Using this method we find the probability that a median score difference of 1185 is zero, therefore showing that Rock’n’roll is still very much alive.
Also tested was whether the debut ranking of a song has an affect on its overall performance. The top 10% of tracks over the year debuted at a median ranking of 76.5, about 5 points higher than for all songs. Using the shuffle method again, we find the probability of this occuring is less than 3%, so there is a correlation between debut ranking and overall performance.
Interestingly, the top performing song of all of 2000 - Faith Hill’s Breathe - never reached the number spot. It only made it to number 2, but it had very long legs, staying in the charts for over 50 weeks. Timing in relation to other hit songs appears to have a strong influence on peak position, but not on overall performance. It would seem a short lived hit can keep a popular song with legs from reaching the top spot, but not from being the years top track.
Link to the jupyter notebook.